
|
|||||
|

<< Volver Ir a "detalles" Fase de Captura >>
Vamos por partes, como dijo JackLas Distintas Fases y Modos de Funcionamiento
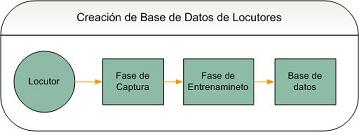
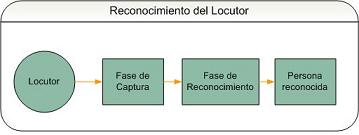
Modo 1 : Creación de Base de Datos de LocutoresSin una base de datos, el programa no tendrá a quien reconocer. Antes de comenzar reconociendo personas, debemos ingresar los datos de uno o más locutores y grabarlos hablando (uno a la vez, lógicamente). El programa se encargará de reconocer las características de su voz y guardarlas en una base de datos, para futuras comparaciones (reconocimiento). Modo 2 : Reconocimiento de un LocutorUna vez que tenemos una base de datos con una o más personas, podremos grabar a un locutor hablando y pedirle al programa que revise si aquella persona está o no en la base de datos. Si la persona se encuentra, entonces el programa dirá de quien se trata. VoxID te 0yeFase de CapturaPara esta fase es necesario que el usuario ingrese un archivo de audio (.wav) con la voz del locutor diciendo una palabra de entre 6-10 letras (ver palabras sugeridas en el manual del usuario). También puede grabarse un nuevo archivo usando un micrófono. El programa tomara la señal de audio y la procesará utilizando herramientas bien conocidas de la ingeniería de procesamiento de señales. VoxID te ModelaFase de EntrenamientoLa señal procesada será ingresada a la fase de entrenamiento como un set de vectores de características. Estos vectores se pasan a un algoritmo genético que, junto con un algoritmo de expectation maximization, intentará crear un set de gaussianas multidimensional que modele la distribución de estos puntos de entrada en un espacio multidimensional (que se conoce como GMM - gaussian mixture model). Los modelos para cada persona se almacenarán en una base de datos. VoxID te ReconoceFase de ReconocimientoLuego de haber realizado el mismo procesamiento de señal mencionado en la fase de captura, los vectores de características son ingresados a cada modelo almacenado en la base de datos. El resultado será un número por cada modelo, el cual indica cuanto se acerca la voz del locutor al modelo. El mayor número indica a quién corresponde, con mayor probabilidad, el locutor. Finalmente, se determina si la probabilidad supera un valor mínimo y, si lo hace, se indica el nombre del locutor identificado. Esta última medida permite indicarle al usuario, cuando existe un caso en que el programa no ha reconocido a la persona, por no encontrarse en la base de datos. |
 Existen dos tareas que realizaremos con nuestro programa:
Existen dos tareas que realizaremos con nuestro programa:
Página diseñada por Tomás Girardi, Roberto Vargas y Pablo Benaprés. - Contacto : tgirardi [ @ ] gmail.com - Última Actualización : 06/07/08


|