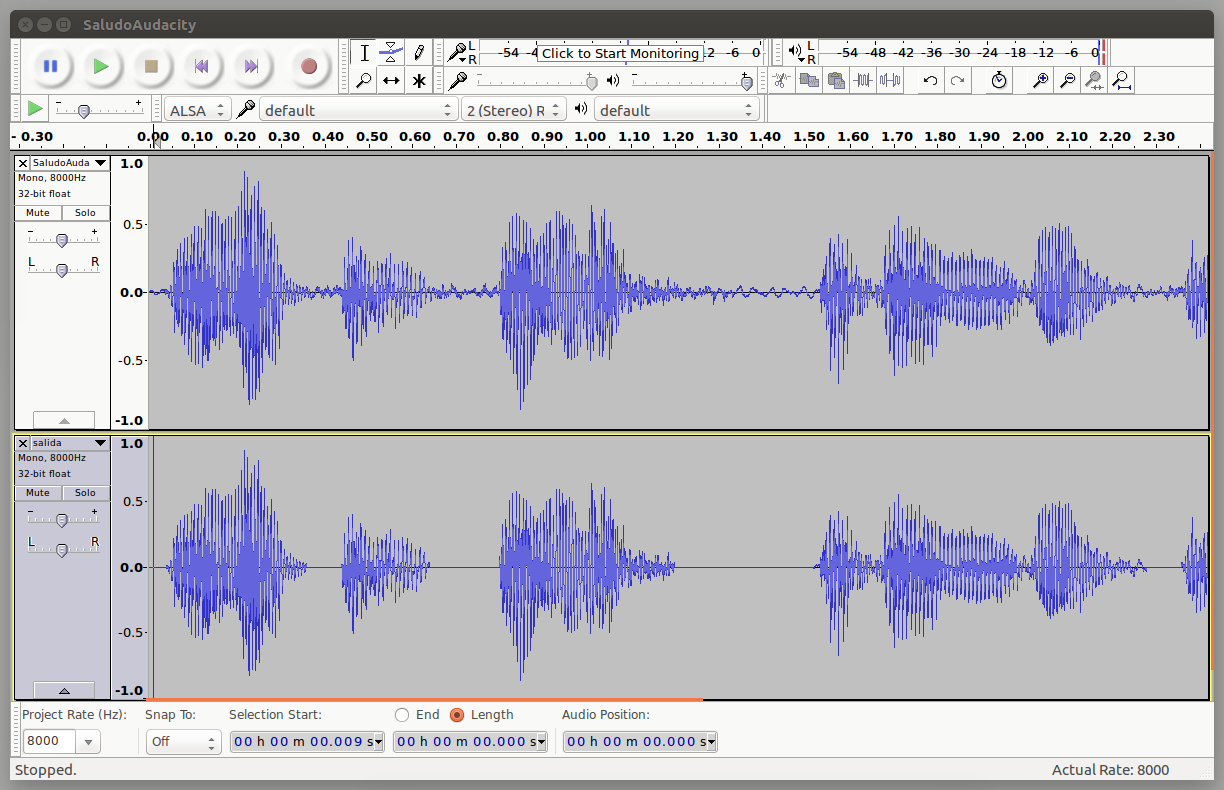
Figura 1: Señal de archivo saludo. Superior: segmento de señal original; señal inferior: misma señal con segmentos de silencio de 40 [ms] removidos.
Objetivos:
En esta tarea usted aplicará: creación de procesos, manejo de señales, comunicación entre
procesos usando pipes
e integración de servicios provistos por otras aplicaciones. En este
caso se solicitará servicios de GNU octave y aplay (Player for ALSA
sound-card driver, Linux).
Introducción
La transmisión de audio paquetizado utiliza técnicas de
detección de la actividad de la voz (Voice Activity Detection -VAD-)
para remover los paquetes con ausencia de señal de voz y así disminuir
el uso de los recursos ocupados en la comunicación extremo a extremo.
Varias técnicas han sido propuestas para detectar la actividad de la
voz [1]. El objetivo de esta tarea es ejercitar mecanismos ofrecidos en
algunos sistemas operativos para comunicar procesos y requerir
servicios de aplicaciones y herramientas instaladas en un sistema. Para
dar un contexto de aplicación, en esta tarea su grupo aplicará una
técnica de detección de la voz descrita en [1] que se basa en una medición de la
distribución de la energía del espectro de la señal de audio. En esta técnica, se dice que un paquete contiene voz si el
cociente de la suma de las componentes espectrales entre 125 [Hz] y
1000 [Hz] sobre la suma de todas las componentes espectrales supera un
umbral dado. Cuando esta situación es deteectada, los sistemas de
comunicaciones suelen enviar un paquete muy pequeño para señalar al
extremo receptor de la presencia de silencio, ante lo cual el recpetor
reproduce una señal de ruido de nivel confortable para que la persona
no crea que la comunicación se perdió. En esta tarea no cubriremos todo
aquello, su grupo deberá reemplazar los paquetes de silencio por una
señal nula y se reproducirá la versión original y aquella con el
silencio removido. Formas de onda de una señal original y otra con silencio removido se muestran en la Figura 1.
Recordar que el foco es experimentar con los mecanismos útiles en la programación de sistemas, no llegar a una solución óptima para el problema.
Nombre: assr : removedor de silencio en stream de audio (audio stream silence removal).Sintaxis: assr
<archivo_de_audio_original> <fracción de energía en parte baja
de espectro> <tamaño de paquete> <offset> [p]
El archivo de audio original contiene muestras de audio mono canal en formato PCM, little endian,
con signo y de 16 bits. La frecuencia de muestreo debe ser de 8KHz.
Puede usar este archivo de ejemplo o generar el suyo usando aplicaciones como Audacity.
La fracción de energía en la parte baja del espectro
es un número real y corresponde al umbral usado para
declarar que un paquete contiene silencio (aquel cuya fracción supere este umbral). Para cada paquete este
umbral será comparado con el cociente entre la energía del especto en
el rango de frecuencia de 125 [Hz] a 1000 [Hz] sobre el total de la
energía de la señal (es decir la suma de todas las bandas de
frecuencia).
El tamaño del paquete es el
número de muestras de audio a ser analizada cada vez. Se sugiere usar
valores entre 160 y 320 muestras equivalentes a 20 y 40 [ms] de audio a
8[KHz].
Offset permite especificar el tiempo en [ms] desde el inicio del archivo a mostrar en los gráficos generados por la aplicación.
Si el parámetro p es
ingresado, assr reproduce el archivo de audio completo luego de reemplazadar por ceros los paquetes de silencio como se muestra en la Figura 1.