![]()
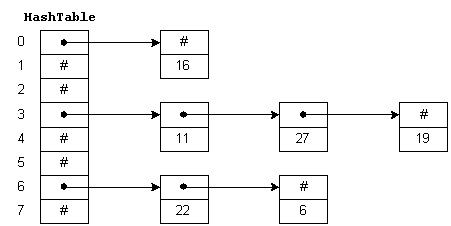
To insert a new item in the table, we hash the key to determine which list the item goes on, and then insert the item at the beginning of the list. For example, to insert 11, we divide 11 by 8 giving a remainder of 3. Thus, 11 goes on the list starting at HashTable[3]. To find a number, we hash the number and chain down the correct list to see if it is in the table. To delete a number, we find the number and remove the node from the linked list.
Entries in the hash table are dynamically allocated and entered on a linked list associated with each hash table entry. This technique is known as chaining. An alternative method, where all entries are stored in the hash table itself, is known as direct or open addressing and may be found in the references.
If the hash function is uniform, or equally distributes the data keys among the hash table indices, then hashing effectively subdivides the list to be searched. Worst-case behavior occurs when all keys hash to the same index. Then we simply have a single linked list that must be sequentially searched. Consequently, it is important to choose a good hash function. Several methods may be used to hash key values. To illustrate the techniques, I will assume unsigned char is 8-bits, unsigned short int is 16-bits and unsigned long int is 32-bits.
typedef int HashIndexType;
HashIndexType Hash(int Key) {
return Key % HashTableSize;
}
For example, if HashTableSize is 1024 (210), then a 16-bit index is sufficient and S would be assigned a value of 16 - 10 = 6. Thus, we have:/* 8-bit index */ typedef unsigned char HashIndexType; static const HashIndexType K = 158; /* 16-bit index */ typedef unsigned short int HashIndexType; static const HashIndexType K = 40503; /* 32-bit index */ typedef unsigned long int HashIndexType; static const HashIndexType K = 2654435769; /* w=bitwidth(HashIndexType), size of table=2**m */ static const int S = w - m; HashIndexType HashValue = (HashIndexType)(K * Key) >> S;
typedef unsigned short int HashIndexType;
HashIndexType Hash(int Key) {
static const HashIndexType K = 40503;
static const int S = 6;
return (HashIndexType)(K * Key) >> S;
}
typedef unsigned char HashIndexType;
HashIndexType Hash(char *str) {
HashIndexType h = 0;
while (*str) h += *str++;
return h;
}
typedef unsigned char HashIndexType;
unsigned char Rand8[256];
HashIndexType Hash(char *str) {
unsigned char h = 0;
while (*str) h = Rand8[h ^ *str++];
return h;
}
typedef unsigned short int HashIndexType;
unsigned char Rand8[256];
HashIndexType Hash(char *str) {
HashIndexType h;
unsigned char h1, h2;
if (*str == 0) return 0;
h1 = *str; h2 = *str + 1;
str++;
while (*str) {
h1 = Rand8[h1 ^ *str];
h2 = Rand8[h2 ^ *str];
str++;
}
/* h is in range 0..65535 */
h = ((HashIndexType)h1 << 8)|(HashIndexType)h2;
/* use division method to scale */
return h % HashTableSize
}
| size | time | size | time | |
|---|---|---|---|---|
| 1 | 869 | 128 | 9 | |
| 2 | 432 | 256 | 6 | |
| 4 | 214 | 512 | 4 | |
| 8 | 106 | 1024 | 4 | |
| 16 | 54 | 2048 | 3 | |
| 32 | 28 | 4096 | 3 | |
| 64 | 15 | 8192 | 3 |