![]()
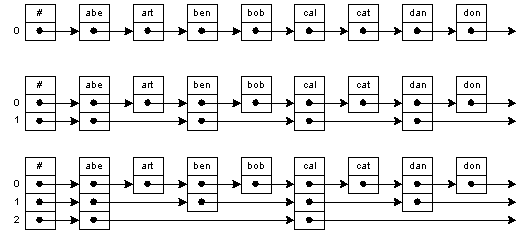
The indexing scheme may be extended as shown in the bottom figure, where we now have an index to the index. To locate an item, level-2 pointers are traversed until the correct segment of the list is identified. Subsequently, level-1 and level-0 pointers are traversed.
During insertion the number of pointers required for a new node must be determined. This is easily resolved using a probabilistic technique. A random number generator is used to toss a computer coin. When inserting a new node, the coin is tossed to determine if it should be level-1. If you win, the coin is tossed again to determine if the node should be level-2. Another win, and the coin is tossed to determine if the node should be level-3. This process repeats until you lose. If only one level (level-0) is implemented, the data structure is a simple linked-list with O(n) search time. However, if sufficient levels are implemented, the skip list may be viewed as a tree with the root at the highest level, and search time is O(lg n).
The skip list algorithm has a probabilistic component, and thus a probabilistic bounds on the time required to execute. However, these bounds are quite tight in normal circumstances. For example, to search a list containing 1000 items, the probability that search time will be 5 times the average is about 1 in 1,000,000,000,000,000,000.
To initialize, initList is called. The list header is allocated and initialized. To indicate an empty list, all levels are set to point to the header. Function insertNode allocates a new node, searches for the correct insertion point, and inserts it in the list. While searching, the update array maintains pointers to the upper-level nodes encountered. This information is subsequently used to establish correct links for the newly inserted node. The newLevel is determined using a random number generator, and the node allocated. The forward links are then established using information from the update array. Function deleteNode deletes and frees a node, and is implemented in a similar manner. Function findNode searches the list for a particular value.