 Algoritmos de Compresión de Video
Algoritmos de Compresión de Video
Teoría y Estándares
Resumen: El siguiente trabajo
introduce a los alumnos del curso Programación de Sistemas en los
distintos algoritmos de compresión de video, estándares,
arquitecturas y codecs usados, dándoles un marco de conocimiento
teórico sobre el tema, incluyendo parámetros de
comparación, ventajas y desventajas de unos y otros.
Introducción:
Hoy en día, el uso,
transmisión y capacidad de almacenamiento de información ha ido
creciendo exponencialmente con el desarrollo de la tecnología. Con la masificación
de la telefonía móvil, el uso de Internet, el bajo costo de
acceso a mas ancho de banda y de los medios de almacenaje; ha hecho que los
información audiovisual sea muy apetecida por todos los usuarios con
acceso a toda esta tecnología.
Es
por esto que para poder lograr difundir grandes cantidades de
información audiovisual, se ha hecho necesario crear y desarrollar
más y mejores algoritmos de compresión de video, logrando con los
últimos grandes tasas de compresión con muy bajo deterioramiento
de la imagen. Desarrollándose varios métodos de compresión
de video, como por ejemplo el H.26x, M-JPEG, MPG, Ogg
Theora; con dos técnicas comunes de
compresión con perdida, por codecs de transformación o por codecs
predictivos. La compresión de Vídeo para aplicaciones va desde la
producción y difusión de televisión digital hasta la
gestión de datos multimedia, pasando por utilidades interactivas como
pueden ser la videoconferencia a través de telefonía móvil
o la recepción de televisión en una PALM.
Teoría y Estándares:
Algoritmos de
compresión se llama a cualquier procedimiento de codificación que
tenga como objetivo representar cierta cantidad de información
utilizando una menor cantidad de la misma. Las técnicas de
compresión pueden clasificarse en dos grupos, las que son reversibles (lossless) y las que son irreversibles (lossy).
Las reversibles son aquellas en las que después del proceso de
compresión/ descompresión los datos resultantes no han sufrido
ninguna degradación ni pérdida de calidad. Las irreversibles son
aquellas en las cuales una vez realizado el proceso de compresión/
descompresión el contenido resultante ha sufrido una degradación
mas o menos perceptible. En la mayoría de aplicaciones audiovisuales se
debe utilizar técnicas irreversibles, ya que éstas son las que
permiten elevados factores de compresión. Dentro de las técnicas
de compresión irreversibles las más utilizadas e inmediatas son
aquellas que consisten en eliminar información reduciendo el
tamaño de la imagen, eliminando fotogramas (temporal) o asignando menor
cantidad de bits al codificar cada píxel. Existen dos técnicas
comunes de compresión con pérdida:
·
Por códecs de transformación: Los datos originales
son transformados de tal forma que se simplifican (sin posibilidad de regreso a
los datos originales). Creando un nuevo conjunto de datos proclives a altas
razones de compresión sin pérdida.
·
Por códecs predictivos: Los datos originales son analizados
para predecir el comportamiento de los mismos. Después se compara esta
predicción con la realidad, codificando el error y la información
necesaria para la reconstrucción. Nuevamente, el error es proclive a
altas razones de compresión sin pérdida.
La compresión temporal consiste en analizar una secuencia de
vídeo para que en lugar de transmitir todos los fotogramas consecutivos
tan solo se codifique un fotograma y la diferencia entre éste y sus
fotogramas cercanos. Por ejemplo, se codifica el fotograma 1 entero y en lugar
de codificar el fotograma 2 tan solo se codifica aquella información que
es distinta entre los fotogramas 1 y 2. Esto permite que en aquellas secuencias
en las que la información es muy redundante (o sea existen muy pocas
variaciones entre fotogramas consecutivos) se consigan factores de compresión
muy elevados, ya que la diferencia entre ellos es prácticamente nula. La
mayoría de las técnicas de compresión temporal que se
utilizan en la actualidad no se basan tan sólo en la codificación
de la diferencia entre fotogramas consecutivos, sino que lo que codifican es la
diferencia entre un fotograma y la predicción del siguiente, lo cual
eleva mucho el cómputo del procesado y permite obtener a cambio un flujo
de datos mucho más reducido y una imagen de calidad óptima.
El uso de estas técnicas se encuentra tanto en aplicaciones
de televisión digital con relaciones de compresión que no suelen
superar los 10:1 y sin una aparente pérdida de calidad de imagen como en
aplicaciones multimedia con factores de compresión que pueden llegar a
ser de 200:1. Estas técnicas de compresión orientadas al sector
multimedia se encuentran implementadas en pequeñas aplicaciones llamadas
codecs. Los
codecs derivan de las palabras compressor y decompressor, y son los módulos de software que
permiten la compresión y descompresión de los ficheros de audio y
vídeo pequeños programas que incorporan los procesos necesarios
para la compresión de una señal. Existe una gran cantidad de
codecs, esto supone que una misma secuencia de vídeo puede tener
calidades distintas en función del codec utilizado para comprimirla
aunque en todas ellas se haya utilizado la misma arquitectura. Algunos de los
codecs más conocidos son el Cinepack, Indeo 3.2, Indeo 4.1, 4.2 y 4.3, Indeo 5.1 y 5.2, Microsoft RLE, Sorenson,
DivX, Intel YUV9.
Para que no existan problemas a la hora de intercambiar archivos
comprimidos es necesario que se encuentren ubicados en una arquitectura
definida mediante un estándar, de manera que se garantice la correcta
generación, transmisión, almacenamiento y visualización de
los contenidos entre distintos ordenadores. En realidad las primeras
arquitecturas que aparecieron y que se han acabado convirtiendo en
estándar son las estructuras AVI (Audio Video Interleave)
de Microsoft y la estructura QuickTime de Apple.
Posteriormente se creó el estándar MPEG.
La finalidad de una arquitectura como AVI y QuickTime es la de
permitir que los desarrolladores puedan integrar de forma sencilla aplicaciones
de compresión y descompresión de materiales multimedia sobre cada
sistema operativo. En principio aceptan cualquier tipo de compresor o
técnica de compresión de vídeo, siempre que el
desarrollador del código siga las normativas definidas para la correcta
integración del codec sobre cada sistema operativo.
Los métodos de compresión de video con perdida mas
utilizados son:
·
H.261: Es el estándar más usado internacionalmente
para vídeo-conferencia (estándar ITU). Diseñado para RDSI,
se suele usar junto con otros estándares de control como H.230, H.221,
etc. Soporta QCIF (144x176) y CIF (288x352).
·
H.264: O MPEG-4 parte 10, es un códec digital de alta
compresión estándar escrito por el ITU-T Video Coding Experts Group (VCEG) junto con el ISO/IEC Moving
Picture Experts Group (MPEG) como producto del
esfuerzo de colaboración colectivo conocido como Joint
Video Team (JVT). El estándar ITU-T H.264 y el estándar ISO/IEC
MPEG-4 part 10 (formalmente ISO/IEC 14496-10) son
técnicamente idénticos, y la tecnología es conocida
también como AVC (codificación de video avanzada).
H.264 es el
nombre afín a la línea ITU-T de estándares para video
H.26x, mientras que AVC se relaciona con la parte del proyecto del grupo
ISO/IEC MPEG que completó el trabajo del estándar tras el
desarrollo inicial realizado en
La
intención del proyecto H.264/AVC fue crear un estándar que sea
capaz de proveer de una buena calidad de imagen con bit
rates substancialmente menores (p.ej.
la mitad o menos) que los estándares previos (p.ej.
el MPEG-2, H.263 o MPEG-4 parte 2). Además de no incrementar la
complejidad para que el diseño sea impracticable (demasiado caro) de
implementar. Otro objetivo fue que el estándar fuera lo suficientemente
flexible para ser aplicado a una gran variedad de aplicaciones (p.ej. para altos y bajos bit rates o resoluciones de imagen) y para trabajar
correctamente en una gran variedad de redes y sistemas (p.ej.,
para radiodifusión, almacenamiento DVD, redes de paquetes RTP/IP o
sistemas de telefonía multimedia).
·
OGG THEORA: Formato de compresión de video con pérdida,
abierto y libre de patentes. Está siendo desarrollado por el Proyecto Ogg, básicamente es una adaptación del
formato recientemente liberado VP3 para encapsularlo dentro del formato
contenedor Ogg, y mejora ligera del códec. El
objetivo es la posibilidad de tener ficheros de video Ogg
con el audio en formato Ogg-Vorbis
y el video Ogg-Theora,
pudiendo trabajar con audio y video a la vez sin tener que maniobrar con
formatos cerrados y/o de pago.
·
M-JPEG (Motion JPEG): es una versión extendida del algoritmo
JPEG que comprime imágenes. Básicamente consiste en tratar al
vídeo como una secuencia de imágenes estáticas independientes
a las que se aplica el proceso de compresión del algoritmo JPEG una y
otra vez para cada imagen de la secuencia de vídeo. Existen cuatro modos
de operación para el JPEG: secuencial, progresiva, sin pérdida, y
jerárquica. Normalmente se utiliza el modo secuencial.
La ventaja es
que se puede realizar en tiempo real e incluso con poca inversión en
hardware. El inconveniente de este sistema es que no se puede considerar como
un estándar de vídeo pues ni siquiera incluye la señal de
audio. Otro problema es que el índice de compresión no es muy
grande.
JPEG utiliza
una técnica de compresión espacial, la intracuadros
o DCT. El sistema JPEG solamente utiliza la compresión espacial al estar
diseñado para comprimir imágenes individuales.
Motion-JPEG es
el método elegido para las aplicaciones donde se envía la misma
información a todos los usuarios, las broadcast.
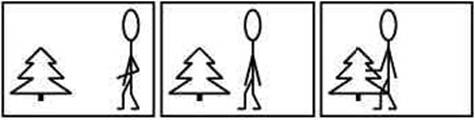
Ejemplo
de secuencia de video
·
MPEG: Es una de las técnicas de vídeo y audio más
conocidas; el estándar denominado MPEG (iniciado por el Motion Picture Experts Groups a finales de los
años 80).
El algoritmo
que utiliza además de comprimir imágenes estáticas compara
los fotogramas presentes con los anteriores y los futuros para almacenar
sólo las partes que cambian.
MPEG aplica la
compresión temporal y la espacial. En primer lugar se aplica una
transformada de coseno discreta, seguida de una cuantización para
finalmente comprimir mediante un algoritmo RLE. Los bloques de imagen y los de
predicción de errores tienen una gran redundancia espacial, que se
reduce gracias a la transformación de los bloques desde el dominio del
espacio al dominio de frecuencia.
Existen
diferentes opciones dependiendo del uso:
MPEG-1 fue presentado en 1993 y está dirigido a
aplicaciones de almacenamiento de vídeo digital en CD’s.
Por esta circunstancia, la mayoría de los codificadores y
decodificadores MPEG-1 precisan un ancho de banda de aproximadamente 1.5 Mbit/segundo a resolución CIF (352x288
píxeles).
MPEG-1 guarda
una imagen, la compara con la siguiente y almacena sólo las diferencias.
Se alcanzan así grados de compresión muy elevados. Define tres
tipos de fotogramas:
Fotogramas I o Intra-fotogramas,
son los fotogramas normales o de imagen fija, proporcionando una
compresión moderada, en JPEG. Fotogramas P o Predichos: son imágenes predichas a partir de la
inmediatamente anterior. Se alcanza una tasa de compresión muy superior.
Fotogramas B o bidireccionales:
se calculan en base a los fotogramas inmediatamente anterior y posterior.
Consigue el mayor grado de compresión a costa de un mayor tiempo de
cálculo. Estándar escogido por Vídeo-CD: calidad VHS con
sonido digital.
Una secuencia
típica de I -, B- y P-frames puede tener un
aspecto similar al del dibujo de abajo. Tenga en cuenta que un P-frame puede solo referenciar a un I - o P-frame anterior, mientras que un B-frame
puede referenciar tanto a I - o P-frames anteriores y
posteriores.
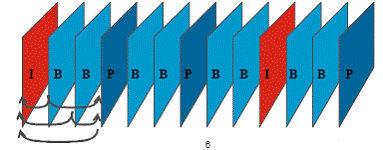
En la imagen
de abajo se ilustra como se transmite la información relativa a las
diferencias entre las imágenes 2 y 3 respecto a la de referencia.
MPEG-2 fue aprobado en 1994 como estándar y fue
diseñado para vídeo digital de alta calidad (DVD), TV digital de
alta definición (HDTV), medios de almacenamiento interactivo (ISM),
retransmisión de vídeo digital (Digital Vídeo Broadcasting, DVB) y Televisión por cable (CATV). El
proyecto MPEG-2 se centró en ampliar la técnica de
compresión MPEG-1 para cubrir imágenes más grandes y de
mayor calidad con un nivel de compresión menor y un consumo de ancho de
banda mayor. MPEG-2 también proporciona herramientas adicionales para
mejorar la calidad del vídeo consumiendo el mismo ancho de banda, con lo
que se producen imágenes de muy alta calidad cuando lo comparamos con
otras tecnologías de compresión. El ratio de imágenes por
segundo está bloqueado a 25 (PAL)/30 (NTSC) ips.
al igual que en MPEG-1.
Con MPEG-2
pueden conseguirse elevados ratios de hasta 100:1, dependiendo de las
características del propio vídeo.
MPEG-2
normalmente define dos sistemas de capas, el flujo de programa y el flujo de
transporte. Se usa uno u otro pero no los dos a la vez. El flujo de programa
funcionalmente es similar al sistema MPEG-1. La técnica de
encapsulamiento y multiplexación de la capa de compresión produce
paquetes grandes y de varios tamaños. Los paquetes grandes producen
errores aislados e incrementan los requerimientos de buffering en el
receptor/decodificador para demultiplexar los flujos de bits. En
contraposición el flujo de transporte consiste en paquetes fijos de 188
bytes lo que decrementa el nivel de errores ocultos.
MPEG-3 fue diseñado originalmente para HDTV
(Televisión de Alta Definición), pero abandonado posteriormente a
favor de MPEG-2.
MPEG-4 fue aprobado en 2000 y es uno de los desarrollos
principales de MPEG-2. Profundizaremos en MPEG-4 para comprender mejor
términos y aspectos.
MPEG-4 Parte 2 (MPEG-4 Visual): Cuando la gente habla de
MPEG-4 generalmente se está refiriendo a MPEG-4 parte 2. Este es el
estándar de transmisión de vídeo clásico MPEG-4,
también denominado MPEG-4 Visual. Como uno de los desarrollos
principales de MPEG-2, MPEG-4 incorpora muchas más herramientas para
reducir el ancho de banda preciso en la transmisión para ajustar una
cierta calidad de imagen a una determinada aplicación o escena de la
imagen. Además el ratio de imágenes por segundo no está
bloqueado a 25 (PAL)/30 (NTSC) ips. Es importante
destacar, no obstante, que la mayoría de las herramientas para reducir
el número de bits que se transmiten son sólo relevantes para las
aplicaciones en tiempo no real. Esto es debido a que alguna de las nuevas
herramientas necesitan tanta potencia de proceso que el tiempo total de
codificación/decodificación (por ejemplo la latencia) lo hace
impracticable para otras aplicaciones que no sean la codificación de películas,
codificación de películas de animación y similares. De
hecho, la mayoría de las herramientas en MPEG-4 que pueden ser usadas en
aplicaciones en tiempo real son las mismas herramientas que están
disponibles en MPEG-1 y MPEG-2.
Otra mejora de
MPEG-4 es el amplio número de perfiles y niveles de perfiles (explicados
posteriormente) que cubren una variedad más amplia de aplicaciones desde
todo lo relacionado con transmisiones con poco ancho de banda para dispositivos
móviles a aplicaciones con una calidad extremadamente amplia y demandas
casi ilimitadas de ancho de banda. La realización de películas de
animación es sólo un ejemplo de esto.
Perfiles MPEG-4 dado que hay un gran número de
técnicas (herramientas) disponibles en MPEG (especialmente en MPEG-4)
para reducir el consumo de ancho de banda en la transmisión, la variable
complejidad de estas herramientas y el hecho de que no todas las herramientas
sean aplicables a todas las aplicaciones, sería irreal e innecesario
especificar que todos los codificadores y decodificadores MPEG deberían
soportar todas las herramientas disponibles. Por consiguiente se han definido
subconjuntos de estas herramientas para diferentes formatos de imágenes
dirigidos a diferentes consumos de ancho de banda en la transmisión.
Hay diferentes
subconjuntos definidos para cada una de las versiones de MPEG. Por ejemplo hay
un subconjunto de herramientas denominados MPEG Profile. Un MPEG Profile
específico establece exactamente qué herramientas debería
soportar un decodificador MPEG. De hecho los requerimientos en el codificador y
el decodificador no tienen porque hacer uso
de todas las herramientas disponibles. Además, para cada
perfil existen a diferentes niveles. El nivel especifica parámetros como
por ejemplo el ratio de bits máximo
a usar en la transmisión y las resoluciones soportadas. Al especificar
el Nivel y el Perfil MPEG es posible diseñar un sistema que solo use las
herramientas MPEG que son aplicables para un tipo concreto de
aplicación.
MPEG-4 tiene
un amplio número de perfiles diferentes. Entre ellos se encuentran el
Simple Profile y el Advanced Profile que son los más utilizados en
aplicaciones de seguridad. Mientras muchas herramientas se usan para ambos
perfiles, existen algunas diferencias. Por ejemplo, Simple Profile soporta I- y
P- VOPs (frames), mientras
que Advanced Simple Profile soporta los frames I-, B-
y P-VOPs. Otra diferencia entre el Simple y el
Advanced Profile es el soporte a rangos de resoluciones y
a diferentes consumos de ancho de banda, especificados en un
diferente Level. Mientras que el Simple Profile
alcanza resoluciones hasta CIF (352x288 píxeles en PAL) y precisa un
ancho de banda de 384 kbit/segundo (en el nivel L3), Advanced Simple Profile
consigue la resolución 4CIF (704x480 píxeles en PAL) a 8000
kbit/segundo (en el nivel L5).
MPEG-4 Short header y long header: “MPEG-4 short
header” no es más que un método de compresión H.263
encapsulado con cabeceras de transmisión de vídeo MPEG-4.
MPEG-4 short
header no aprovecha ninguna de las herramientas adicionales especificadas en el
estándar MPEG-4. MPEG-4 short header está solo especificado para
asegurar compatibilidad con equipos antiguos que emplean la
recomendación H.263, diseñada para videoconferencia sobre RDSI y
LAN. De forma práctica, el MPEG-4 short header es idéntico a la
codificación/decodificación H.263, que da un nivel de calidad
menor que MPEG-2 y MPEG-
La calidad de
la imagen y del vídeo en “short header” no está
cercana a la del MPEG-4 real, dado que no hace uso de las técnicas que
permiten filtrar información de la imagen que no es visible por el ojo
humano. Tampoco usa métodos como la predicción DC y AC que pueden
reducir de forma significativa las necesidades de ancho de banda.
Para
clarificar una especificación de un sistema de distribución de
vídeo, el soporte a MPEG-
MPEG-4 parte 10 (AVC, Control de Vídeo
Avanzado) MPEG-4 AVC, al que también se refiere como H.264 es un desarrollo
posterior en el que MPEG tiene un conjunto completamente nuevo de herramientas
que incorporan técnicas más avanzadas de compresión para
reducir aun más el consumo de ancho de banda en la transmisión
con una calidad de imagen determinada. Pese a ser más complejo
añade también requerimientos de rendimiento y costes,
especialmente para el codificador, al sistema de transmisión de
vídeo en red. MPEG-4 AVC no se tratará en este documento.
Constant bit-rate
(CBR) y Variable bit-rate
(VBR)
otro aspecto importante de MPEG es el modo en el que se usa el ancho de banda
disponible. En la mayoría de los sistemas MPEG es posible seleccionar si
el ratio de bits debe ejecutarse en modo CBR (constante) o VBR (variable). La
selección óptima depende de la aplicación y de la
infraestructura de red disponible.
Con la
única limitación del ancho de banda disponible el modo preferido
es normalmente CBR, dado que este modo consume un ancho de banda constante en
la transmisión. La desventaja es que la calidad de la imagen
variará y, aunque se mantendrá relativamente alta cuando no hay
movimiento en la escena, la calidad bajará significativamente cuando
aumente el movimiento.
El modo VBR,
por otra parte, mantendrá una alta calidad de imagen, si así se
define, sin tener en cuenta si hay movimiento o no en la escena. Esto es a
menudo deseable en aplicaciones de seguridad y vigilancia en las que hay la necesidad
de una alta calidad, especialmente si no hay movimiento en la escena. Dado que
el consumo de ancho de banda puede variar, incluso si se define una media de
ratio de bits objetivo, la infraestructura de red (el ancho de banda
disponible) necesitará tener esta capacidad para un sistema de este
tipo.
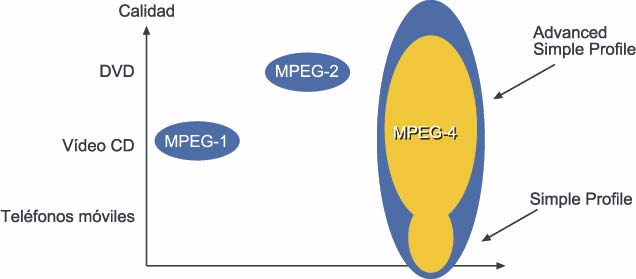
Posicionamiento de MPEG-1, MPEG-2 y MPEG-4
La
ilustración de debajo muestra que el espectro de MPEG-4 es mucho
más amplio en relación a MPEG-1 y MPEG-2 que fueron desarrollados
para aplicaciones más específicas. Mientras MPEG-1 fue
desarrollado para vídeo digital en CD-ROM, MPEG-2 fue desarrollado con
el DVD y la televisión de alta definición en mente. MPEG-4 por
otro lado no está dirigido a aplicaciones específicas y puede ser
apropiado para aplicaciones de animación o para teléfonos
móviles.
Otros formatos como el MPEG-7 y el MPEG-21 están en la
actualidad en pleno desarrollo. Con ellos se pretende generar potentes bases de
datos capaces de gestionar e introducir técnicas de acceso condicional a
contenidos multimedia Actualmente este formato se ha hecho muy popular en
Internet aunque tan solo se esté utilizando una mínima parte de
su potencial (teniendo en cuenta los elevados factores de compresión que
es capaz de soportar) con unos resultados visuales muy satisfactorios. Uno de
los codecs que basa su compresión en algunos de los parámetros
definidos en el estándar es el conocido DivX:
en este caso se considera toda la imagen como un único objeto
rectangular.
CONCLUSIONES
A pesar que con el paso
del tiempo y el avance vertiginoso de la tecnología, los algoritmos de
compresión de video no pueden dar solución única a todos
los casos posibles en que se requiere su aplicación, además de
tener que incurrir en un costo en la mayoría de los casos; las
aplicaciones en la que se requieren van desde la producción y
difusión de televisión digital hasta la gestión de datos
multimedia, pasando por utilidades interactivas como pueden ser la
videoconferencia a través de telefonía móvil, vigilancia
por Internet o la recepción de televisión en una PALM.
Por
todas las características desarrolladas en el presente trabajo es claro
que la mayor utilización es de algoritmos con pérdida con la
tendencia aunque no es tan masivo aún, de utilizar por su transversalidad de aplicaciones, el estándar MPEG-4
en algunas de sus formas. Aunque también se está tendiendo a usar
algoritmos que no sean tan rígidos y de libre acceso, como es el caso de
Ogg-Theora de video junto a
Ogg-Vorbis de audio.
Referencias
1.
http://www.uoc.edu/mosaic/articulos/xavierbonet0804.html
2.
http://es.wikipedia.org/wiki/Algoritmo_de_compresi%C3%B3n_con_p%C3%A9rdida
3.
http://www.axis.com/es/documentacion/compresion_video_es.pdf
4.
http://www.monografias.com/trabajos10/vire/vire.shtml
5.
http://www.axis.com/es/seguridad/compresion.htm