Debido a la creciente demanda por incorporar datos de video en los servicios de telecomunicaciones, y en especial en la industria del entretenimiento, la tecnología del video digital se a transformado en una necesidad. Debido a esto, la transferencia eficiente de este material se convirtió en un problemática no trivial que ha inspirado una gran cantidad de investigación.
El gran problema se resume en que el flujo de datos de imagen y video digital alcanza tipicamente rangos cercanos a los 150 [Mb/s], lo cuál es inceptable por las tecnologías de comunicación masivas de la actualidad. Por esto, desde fines de los años 80 se ha intentado crear técnicas para reducir el flujo de video ,en general, eliminando la redundancia de las imagenes para permitir la transmisión y almacenamiento de manera compacta y eficiente.
Fruto de la investigación, han nacido dos grandes estándares que se mantienen vigentes en la actualidad, los MPEG y los H.26X. Sin embargo, existen muchos problemas que mantienen vigente el trabajo e investigación sobre estos y otros algoritmos para compresión de video.
Para entender la teoría y práctica de los algoritmos de compresión de video, es necesario conocer algunos conceptos basicos de imagen y video digital.
Captura: Las camaras y otros dispositivos usan sensores de color o multiespectral para capturar imagenes de manera similar al ojo humano, esto es captura del color con sensores del tipo RGB.
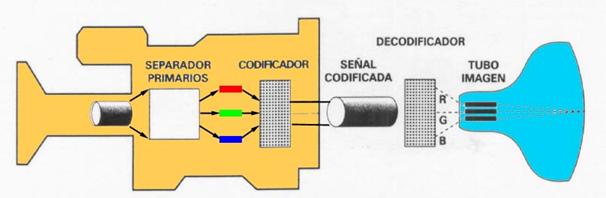
El ojo humano, tiene una capacidad de distinguir una cantidad alrededor de los 4.000.000 de colores, que es perfectamente representable por las tecnologías actuales. Básicamente, el color se procesa haciendo una descomposición de este.
Modelo RGB:
RGB (Red, Green, Blue) hace referencia a la descripción de un color mediante la composición en términos de la intensidad de los colores primarios. Este modelo es posible representar un color mediante la suma (mezcla) de los tres colores primarios de la luz visible.
En la pantalla de un computador, la imagen se describe en un arreglo bidimiensional de píxeles donde cada píxel es un arreglo de 3 puntos (rojo, verde y azul), en el cual cada uno de sus componentes brilla con una intensidad distinta para representar un color. En la actualidad un píxel es descrito por 24 bits (1 byte para cada color primario) que permiten el uso de 16.7 millones de colores en el espacio de color RGB.

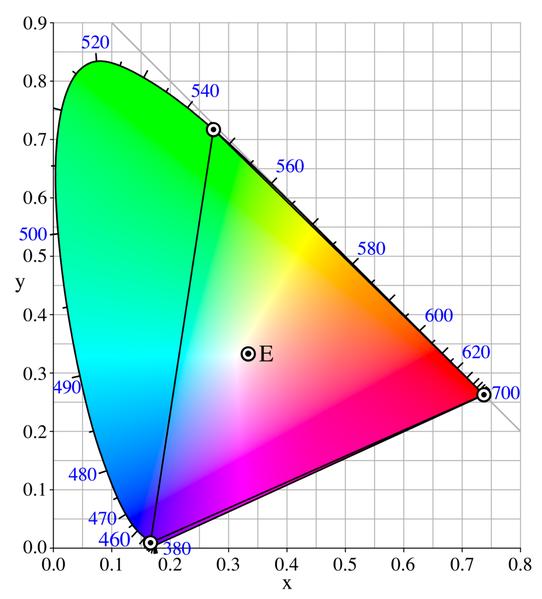
Modelo YUV:
El modelo YUV define el espacio de color en un término de luminancia (Y) y dos de crominancia (U, V). Es ampliamente usado en sistemas análogos de difusión de TV PAL (en NTSC es ligeramente distinto, Modelo YIQ).
Este modelos es más cercano a la percepción humana del color que el modelo RGB. La componente "Y" representa la "luminancia" (o brillo), y U-V representan los componentes de crominancia (color).
Las señales YUV son generadas a partir de las originales RGB:
U = 0.436 * (B - Y) / (1 - 0.114)
V = 0.615 * (R - Y) / (1 - 0.299)
Estas ecuaciones está continuo análisis, así que los coeficientes pueden variar.
Modelo YCbCr:
Este modelo es usado intensamente en la compresión de video, y es derivado del modelo YUV, la componente Y se mantiene sin modificaciones, y las componentes de cromancias son traducidas según la siguiente relación.
Cr=V/1.6+0.5
Conceptos de Video:
Scanning: Una camara de video captura una escéna bidimiensional en movimiento y genera en la salida una señal eléctrica unidimensional. Una escena en movimiento es una colección de imágenes en movimiento, donde cada imagen genera un "frame". El "scanning" comienza en el extremo superior izquierdo y termina en el extremo inferior derecho de la imagen.
El número de lineas escaneadas por imagen se define según un compromiso de ancho de banda , parpadeo y resolución. Incrementar el número de lineas de escaneo por imagen incrementa la resolución espacial. De manera similar, incrementar el número de imágenes por segundo decrementa el parpadeo. Sin embargo, lograr video sin parpadeo y de alta resolución, requiere una gran cantidad de ancho de banda.
Se distinguen dos tipos de scanning:
Progressive-scan: Las scanlines de cada frame son dibujadas en secuencia. Es el método usado en monitores LCD y HDTV.
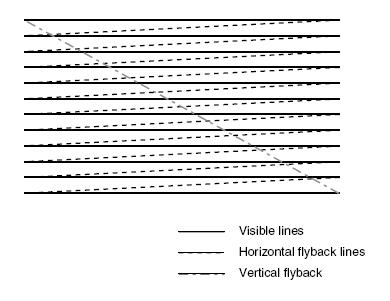
Interlace-scan: Fue introducido en 1930 para reducir el número de scanlines para la transmisión a la mitad de lo que necesita el escaneo progresivo. La técnica consiste en definir dos campos de escaneo que son intercalados primero uno y luego otro, apelando a la persistencia en la visión. Este método es usado en los monitores CRT.
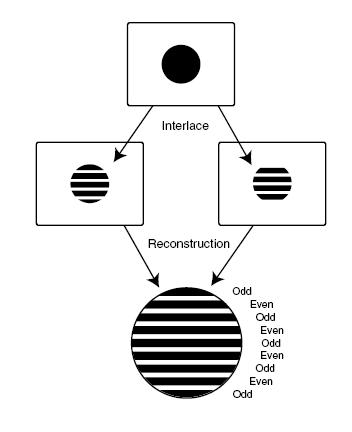

Se llama algoritmo de compresión, a un conjunto de procedimientos secuenciales que permiten representar un flujo de información con una menor cantidad de esta. Se clasifican en dos grandes grupos, los algoritmos de compresión sín pérdidas (lossless) y los algoritmos de compresión con pérdidas (lossy).
Algunos ejemplos de algoritmos standard de compresión sín pérdidas:
Flac Audio
PNG Imagen
TIFF Imagen
Huffyuv Video
MSU Video
LCL Video
Ejemplos de algoritmos standard de compresión con pérdidas:
Fractal compression Imagen
JPEG Imagen
JPEG 2000 Imagen
DjVu Imagen
Flash Video
H.261 Video
H.263 Video
H.264/MPEG-4 AVC Video
Motion JPEG Video
MPEG 1, 2 ,4 Video
Ogg Vorbis Audio
MP2 Audio
MP3 Audio
Algunos algoritmos standard clásicos:
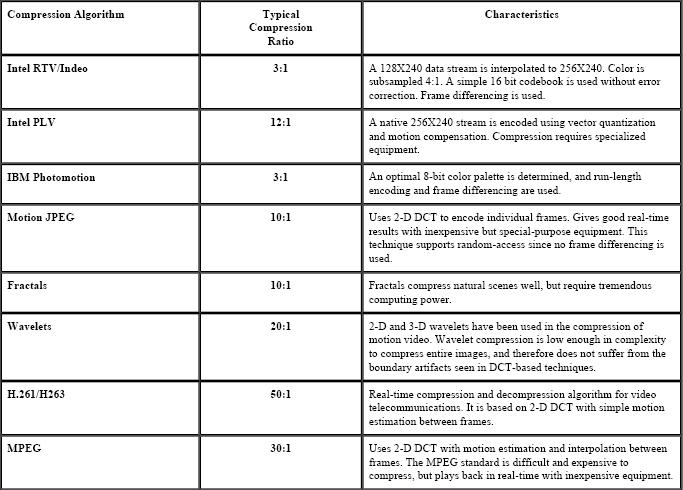
Técnicas de Compresión:
Compresión Espacial: La compresión se hace sobre la información contenida en un frame, y no se relaciona con los otros frames de la secuencia. Este proceso es ampliamente ocupado en formatos de imágenes como, JPEG, GIF y TIFF. El estandar de video digital "Motion JPEG" es un ejemplo de compresión espacial de video.
Compresión Temporal: La dimensión temporal permite buscar información redundante a través de la secuencia de frames, este tipo de compresión es siempre lossy (con pérdidas). La técnica consiste tomar un frame base, y almacenar las diferencias con los frames en la secuencia, sin tomar en cuenta la información redundante. La compresión espacial se usa para definir el frame de partida, el resto de los frames se calcula a partir de las diferencias.
Descripción de MPEG1
Nació a fines de los 80's y se convirtió en el estandar para los VCD's. Todo el resto de la familia MPEG está basado en la compresión de MPEG1.
El diseño se basó sobre la modificación del standard JPEG, añadiendole capacidades de compresión temporal.
Tipos de Frames:
I: Intra frames o Key frames.
Un I-frame es codificado como un frame por separado de los otros de la secuencia. Estos frames son usados para reconstruir otros frames de la secuencia y no tienen relación entre uno y otro, finalmente un video codificado consiste solo en I-frames.
P: Difference Frames o Predicted frame:
Un P-frame es construido usando las diferencias con respecto al I-frame o con respecto al P-frame más reciente. Si sucede un error durante la decodificación, este se propaga por la cascada de P-frames y se acumula, hasta que se vuelva a reconstruir desde otro I-frame.
B: Bidirectional Playback Support.
Un B-frame es codificado usando las diferencias con respecto a un I-frame predecesor y un P-frame sucesor en la secuencia.
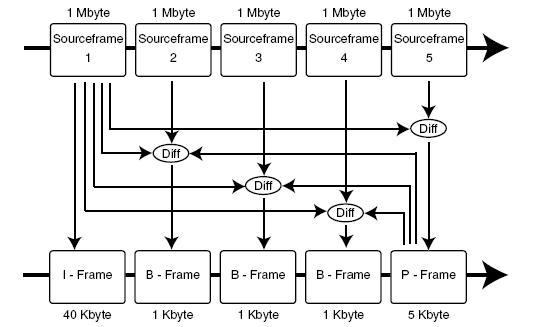

Un grupo de imágenes es una secuencia de entre 10 y 30 frames, que se podría describir como un intervalo entre I-frames. De acuerdo a su relación de dependencia para que los frames sean generados, se defininen grupos abiertos y cerrados.
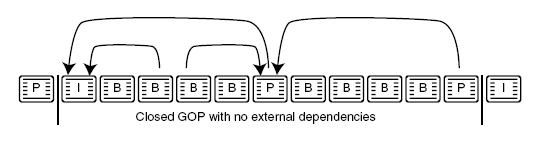
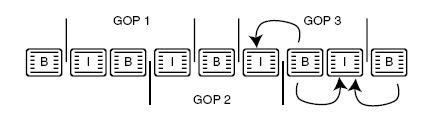
El largo de los GOPs es de vital importancia en la eficiencia de la compresión, GOPs muy cortos implican una mala compresión, y GOPs muy largos disminuyen la calidad de la reproducción (los errores se acumulan). Con la llegada del DVD y su standard MPEG2, los largos son ajustados según las pautas establecidas para los formatos PAL y NTSC DVD, usualmente 15 y 18 (como máximo) respectivamente.
Imagen:
Si la información de la imagen esta en modo RGB, debe ser convertida a Y´CbCr antes de comenzar el proceso de compresión , esto es heredado de JPEG y es vital para la compresión, ya que el ojo humano es más sensible a la componente Y que a las componentes CbCr, esto permite al algoritmo disminuir la cantidad de datos para la representación del color.
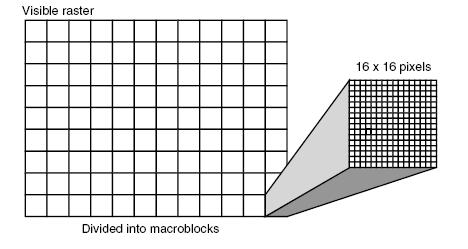
Macrobloques:
Esto se usa para reducir la complejidad en la generación de los B-frames y encontrar fácilmente las áreas de colores idénticos. Un macrobloque se define como un arreglo cuadrado de 16x16 píxeles, que son operados individualmente. Con los macrobloques puede identificar fácilmente cuáles son las redundancias con respecto a un I-frame y un B-frame.

Slice ("rebanada"):
Un slice es un conjunto de macrobloques agrupado según el color promedio que ayuda al decodificador a recuperarse en caso de perder la sincronización, así si se pierde sincronización de un macrobloque, el decodificador recurre a la "rebanada" correspondiente del frame I o P que proporciona el slice asociado a dicho macrobloque.

Entropy Coding:
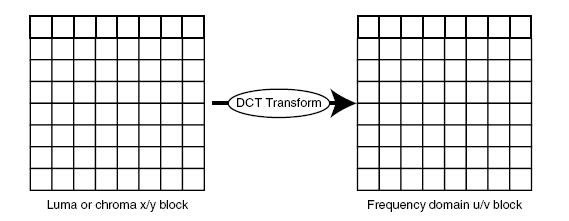
David A. Huffman, publicó en 1952 "A method for the construction of minimun-redundancy codes" que fue la base de lo que hoy se conoce como "Codificación Huffman". En breves palabras, esta codificación permite transformar un texto (o datos en este caso) a una representación de códigos simbólicos de largo variable, es decir, mientras más frecuente (probabilísticamente) sea la información de un macrobloque (ya transformado según DCT), menor sera el largo de su código asociado. Esta técnica constituye el bloque escencial y de gran complejidad (en programación) en el diseño e implementación del algoritmo MPEG.
Diagrama de bloques del codificador MPEG:
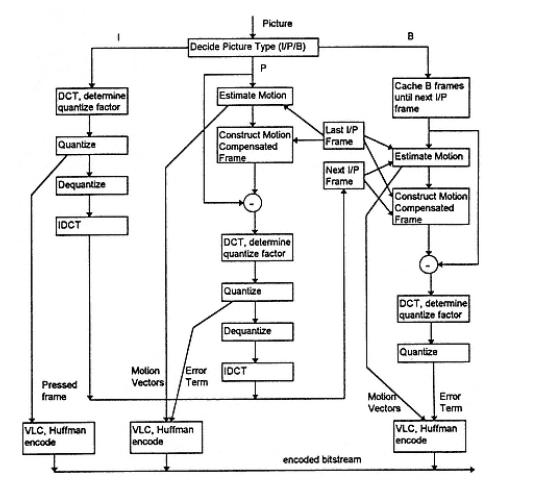
Diagrama de bloques de decodificador MPEG:
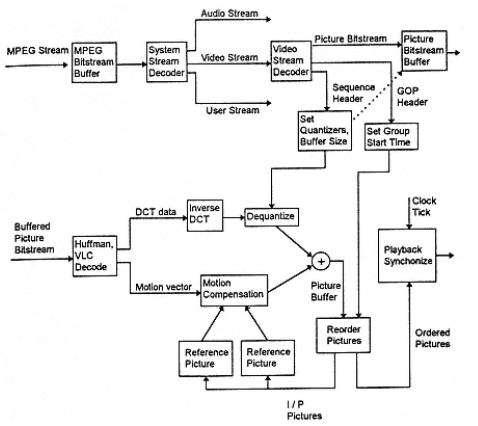
Para desarrollar un programa que pueda decodificar video para su posterior procesamiento, codificación, presentación, etc, comúnmente se usa la librería de código abierto libavcodec, con la cual se han desarrollado proyectos como ffmpeg, la mas usada en el desarrollo de aplicaciones multimedia para linux y windows, como ffdshow, Mplayer, xine, dr. divx, videolan, etc.
El proyecto ffmpeg para linux, esta compuesto de varias partes.
ffmpeg, utilidad de linea de comando para convertir videos de un formato a otro, ademas se puede usar para codificar video desde una tarjeta de tv en tiempo real.
ffserver, un servidor multimedia HTTP para transmisiones en vivo.
ffplay, un reproductor simple basado en las librerias SDL y ffmpeg.
SDL, simple directmedia layer, es una librería multiplataforma que provee acceso de bajo nivel a audio, teclado, video, mouse, joysticks, hardware 3D via opengl, y video 2D, es usado por las aplicaciones de reproducción de MPEG.
SDL soporta Linux, Windows, Windows CE, BeOS, MacOS, Mac OS X, FreeBSD, NetBSD, OpenBSD, BSD/OS, Solaris, IRIX, and QNX.
Libavcodec, la librería que contiene todos los codecs de audio y video, la mayoria desarrollados desde 0.
libavformat, la librería que contiene los generadores y analisadores para todos los formatos comunes de audio y video.
La idea no es inventar la rueda de nuevo, ya que existen muchas aplicaciones que proveen una solución a nuestro problema.
Bibliografía:
- "A practical guide to Video and Audio Compression", Cliff Wootton.
- "Standard Codecs: Image Compression to Advanced Video Coding", Mohammed Ghanbari, IEEE 2003.
- "Real-Time Video Compression: Techniques and Algorithms", Raymond Westwater, Borko Furht.
- www.wikipedia.org
Autores:
Eduardo Alarcón G. lespinoza@elo.utfsm.cl
Luis Enrique Espinoza S. ealarcon@elo.utfsm.cl
Archivos
readme
makefile
avcodec.cpp