Resumen:
Introduccion:
Recursos del curso utilizados en el proyecto:
Octave:
Se utilizo de forma de poder ver por pantalla varias situaciones que se pudiesen presentar en la simulacion. Para la utilización de octave fue necesario el uso de procesos, y la comunicación entre ellos mediante un pipe.
Manejo de procesos:
Para poder ejecutar funciones en paralelo y poder hacer uso de Octave. Se utiliza en dos ocasiones, primero para llamar a Octave , y en una segunda instancia en que se necesita mostrar datos por consola y plotearlos en Octave.
Hilos:
Para el manejo de datos de manera eficiente y como soporte a la comunicación entre procesos. Se utiliza como apoyo para poder enviar los datos a Octave mediante distintas hebras.
Gracias a estos recursos, fue posible visualizar en una pantalla las llegadas de los paquetes, los tiempos de atención, la forma que toman las atenciones de paquetes, entre otros.
Señales: si el programa termina de por un Segmentation Fault o por CTRL+C, se cierra el programa octave-cli.
Para la comprension de estas situaciones es que se adjunta un Diagrama de flujo de alto nivel :
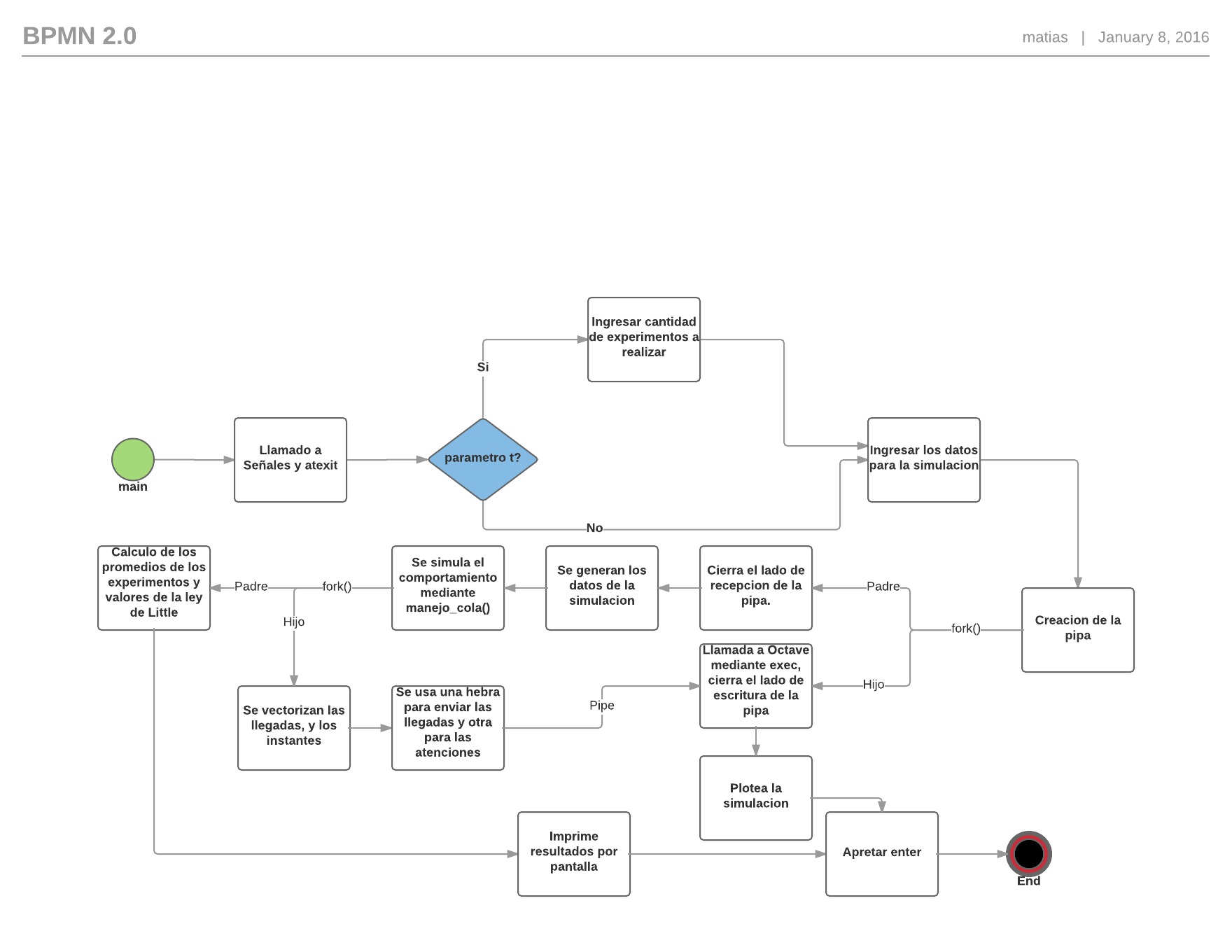{kind=link}
Como existe la necesidad de plotear lineas verticales y no el punto en si, es que se enviaronn los datos de la forma:
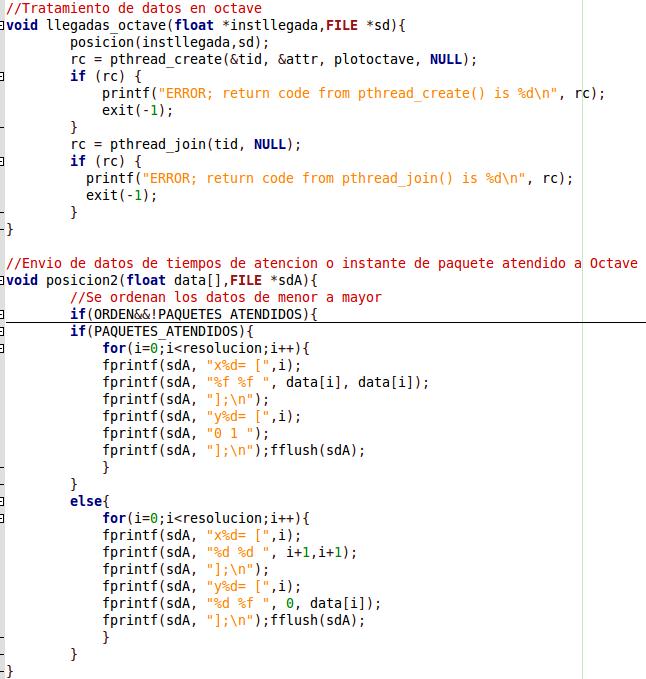{kind=link}
Se utilizo una hebra para enviar las llegadas y otra para las atenciones, asi en caso de que la cantidad de datos sea muy grande no se debia esperar el fin del envio de uno para que se envien los otros.
De la simulacion del servidor:
La simulacion de las Distribuciones de probabilidad fue un punto crucial para un correcto funcionamiento.
Como se carece de conocimientos de simulacion de estos fenomenos en lenguaje C, es que se pidio asesoria a los profesores Werner Creixell y Agustin Gonzalez.
En un principio se malinterpreta la codificacion de estos fenomenos , presentado codigos de las siguientes caracteristicas:
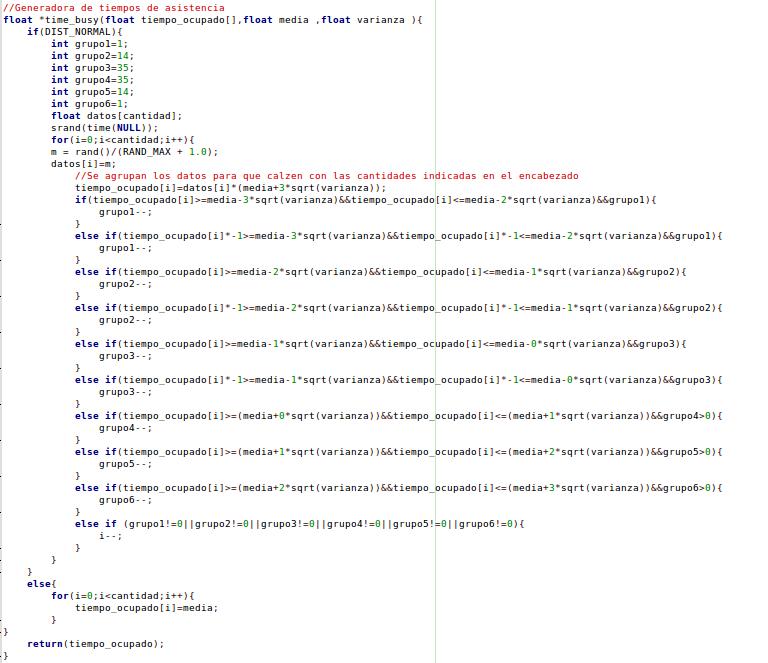{kind=link}
{kind=link}
Las cuales eran aproximaciones a las situaciones planteadas, pero eran ineficientes ya que presentaban desviaciones muy grandes con respecto a lo solicitado por el usuario.
En lugar de ello, se opto por ingresar los datos mediante funciones matematicas eficientes, capaces de entregar desviaciones minimas y apegadas a las necesidades de la situacion:
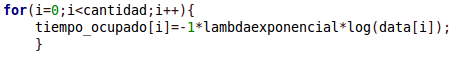{kind=link}
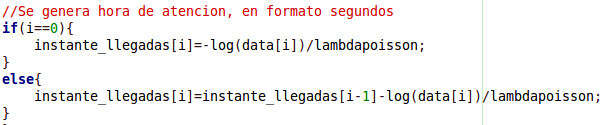{kind=link}
Haciendo esto ademas se logro un significativo ahorro de lineas de codigo.
Para ambos casos, el parametro data[i] corresponde el valor de una distribucion uniforme de la forma:
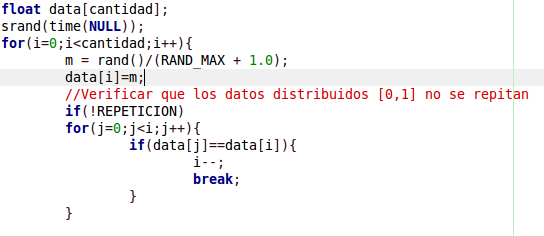{kind=link}
Luego de ello, es que se lograron obtener valores promedio con errores minimos:
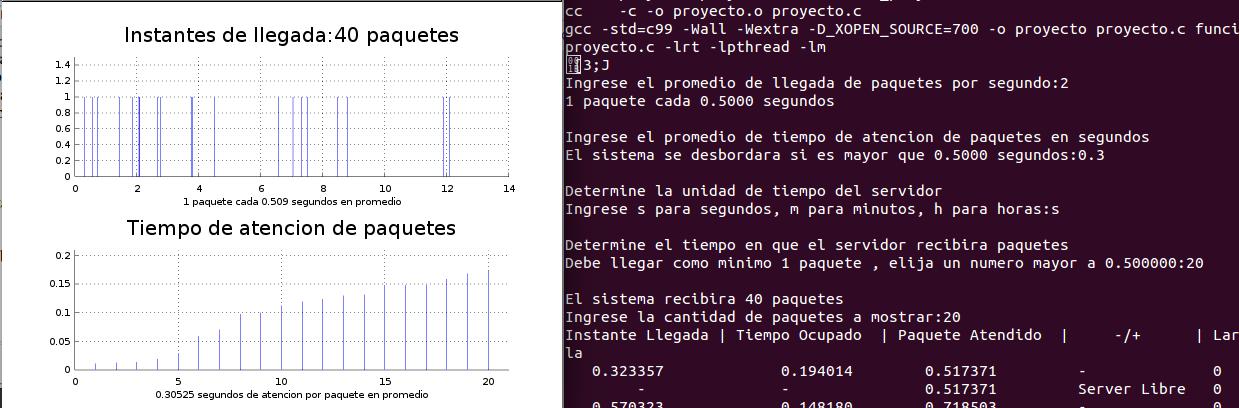{kind=link}
Se ve claramente que para una simulacion con un promedio de 2 paquetes por segundo (0,5 segundos entre llegada de paquetes) y un tiempo de atencion 0.3 s, se obtuvieron medias muy aproximadas (0.509 y 0.30525 respectivamente).
De las opciones de simulacion:
Durante el desarrollo de esta aplicacion , surgieron inquietudes respecto a su funcionamiento que dejaron una seria de opciones utiles para la simulacion.
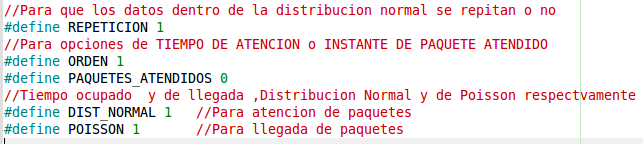
Ellas quedan determinadas en el archivo de cabecera pro.h, en el cual se encuentran las siguientes opciones:
Repetición: indica si queremos que se repitan o no los datos dentro de la distribución “uniforme”, para que así , por ejemplo, se presente la situación de que lleguen dos paquetes en el mismo instante.
Orden: se utiliza para ordenar de mayor a menor los tiempos de atención, para observar la forma de la Distribución exponencial.
Paquetes atendidos: si se activa esta opción, en vez de ver los tiempos de atención, se observa los instantes de atención de cada paquete para poder observar de manera general el comportamiento del servidor.
DIST_NORMAL: desactivando esta opción se generan tiempos de atención de forma determinista, con tiempo igual al lambda de la exponencial, es decir, el ingresado por el usuario.
POISSON: mismo caso que el anterior, solo que para que la llegada de paquetes sea de forma determinista.
Estas ultimas dos opciones son útiles para conocer el comportamiento ideal del servidor y compararlo con las leyes de Little.
{kind=link}
Asi mismo, si el usuario desea repetir el experimento una determinada cantidad de veces, basta con invocar el programa con el parametro "t" a partir de lo cual se eliminan o disminuyen los errores debidos a eventos anomalos.
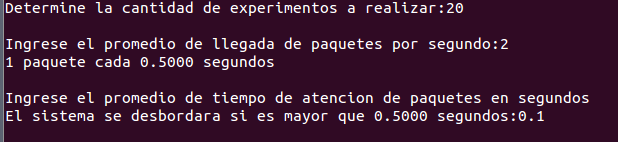{kind=link}
De esta forma, se logro un funcionamiento correcto de la simulacion, en que los errores se minimizaron y que se logro aproximarse a los valores entregados por las leyes de little.
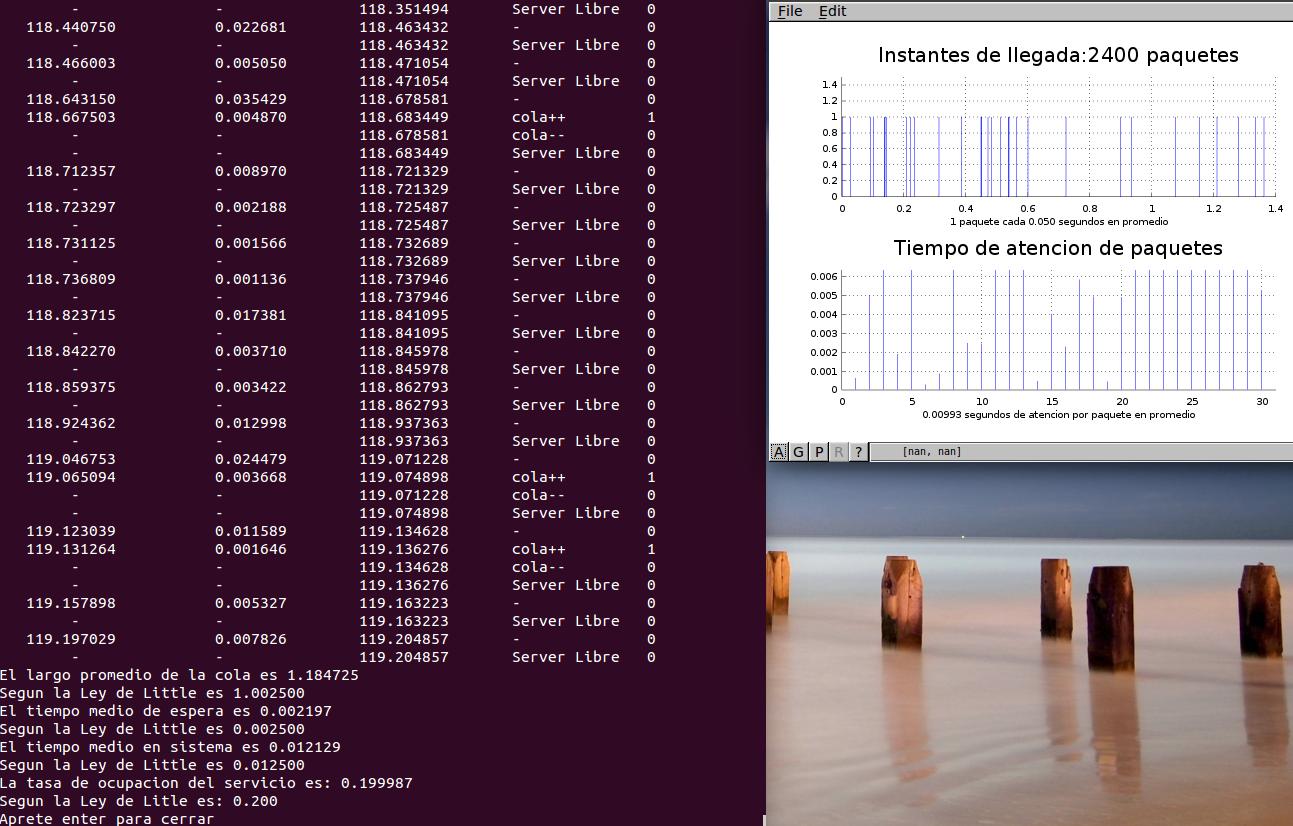{kind=link}
Conclusiones:
Aunque faltan detalles para que el programa funcione en el 100% de los casos, los recursos obtenidos en el curso ayudaron a alcanzar por lo menos un 90% de avance, pues sin ellos no habría sido posible el desarrollo de las herramientas visuales útiles para el entendimiento de este fenómeno particular de colas.
Queda pendiente un orden integral del código, pues a medida que aparecían situaciones problemáticas se iban añadiendo funciones , pero en algunos casos resultaban redundantes.
Queda además explorar en profundidad las bondades del uso de llamados a funciones exec para integrar módulos tal vez mas avanzados para la situación.
El uso de los recursos referidos a Hilos , Hebras y llamado a programas externos fue evidentemente la herramienta mas util para una correcta simulacion debido a que sin ellos el programa quedaria estancado en ocasiones en que el manejo de datos era masivo.
Se entendio ademas, que un servidor en estado "estacionario" es aquel que no se ve sobrepasado por por la cantidad de paquetes que le llegan, por lo que un uso correcto de las leyes de Little serian para servidor con tasa de ocupacion menor al 50% , por ejemplo.