![]()
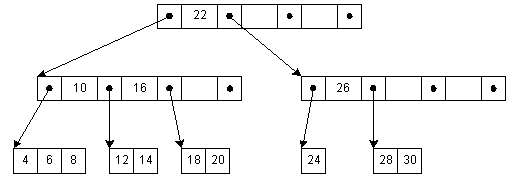
We can locate any key in this 2-level tree with three disk accesses. If we were to group 100 keys/node, we could search over 1,000,000 keys in only three reads. To ensure this property holds, we must maintain a balanced tree during insertion and deletion. During insertion, we examine the child node to verify that it is able to hold an additional node. If not, then a new sibling node is added to the tree, and the child's keys are redistributed to make room for the new node. When descending for insertion and the root is full, then the root is spilled to new children, and the level of the tree increases. A similar action is taken on deletion, where child nodes may be absorbed by the root. This technique for altering the height of the tree maintains a balanced tree.
| B-Tree | B*-Tree | B+-Tree | B++-Tree | |
|---|---|---|---|---|
| data stored in | any node | any node | leaf only | leaf only |
| on insert, split | 1 x 1 –>2 x 1/2 | 2 x 1 –>3 x 2/3 | 1 x 1 –>2 x 1/2 | 3 x 1 –>4 x 3/4 |
| on delete, join | 2 x 1/2 –>1 x 1 | 3 x 2/3 –>2 x 1 | 2 x 1/2 –>1 x 1 | 3 x 1/2 –>2 x 3/4 |
Several variants on the B-tree are listed in Table 4-1. The standard B-tree stores keys and data in both internal and leaf nodes. When descending the tree during insertion, a full child node is first redistributed to adjacent nodes. If the adjacent nodes are also full, then a new node is created, and half the keys in the child are moved to the newly created node. During deletion, children that are 1/2 full first attempt to obtain keys from adjacent nodes. If the adjacent nodes are also 1/2 full, then two nodes are joined to form one full node. B*-trees are similar, only the nodes are kept 2/3 full. This results in better utilization of space in the tree, and slightly better performance.
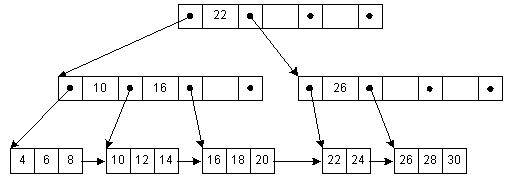
Figure 4-4 illustrates a B+-tree. All keys are stored at the leaf level, with their associated data values. Duplicates of the keys appear in internal parent nodes to guide the search. Pointers have a slightly different meaning than in conventional B-trees. The left pointer designates all keys less than the value, while the right pointer designates all keys greater than or equal to (GE) the value. For example, all keys less than 22 are on the left pointer, and all keys greater than or equal to 22 are on the right. Notice that key 22 is duplicated in the leaf, where the associated data may be found. During insertion and deletion, care must be taken to properly update parent nodes. When modifying the first key in a leaf, the tree is walked from leaf to root. The last GE pointer found while descending the tree will require modification to reflect the new key value. Since all keys are in the leaf nodes, we may link them for sequential access.
The last method, B++-trees, is something of my own invention. The organization is similar to B+-trees, except for the split/join strategy. Assume each node can hold k keys, and the root node holds 3k keys. Before we descend to a child node during insertion, we check to see if it is full. If it is, the keys in the child node and two nodes adjacent to the child are all merged and redistributed. If the two adjacent nodes are also full, then another node is added, resulting in four nodes, each 3/4 full. Before we descend to a child node during deletion, we check to see if it is 1/2 full. If it is, the keys in the child node and two nodes adjacent to the child are all merged and redistributed. If the two adjacent nodes are also 1/2 full, then they are merged into two nodes, each 3/4 full. This is halfway between 1/2 full and completely full, allowing for an equal number of insertions or deletions in the future.
Recall that the root node holds 3k keys. If the root is full during insertion, we distribute the keys to four new nodes, each 3/4 full. This increases the height of the tree. During deletion, we inspect the child nodes. If there are only three child nodes, and they are all 1/2 full, they are gathered into the root, and the height of the tree decreases.
Another way of expressing the operation is to say we are gathering three nodes, and then scattering them. In the case of insertion, where we need an extra node, we scatter to four nodes. For deletion, where a node must be deleted, we scatter to two nodes. The symmetry of the operation allows the gather/scatter routines to be shared by insertion and deletion in the implementation.
The code provided allows for multiple indices to the same data. This was implemented by returning a handle when the index is opened. Subsequent accesses are done using the supplied handle. Duplicate keys are allowed. Within one index, all keys must be the same length. A binary search was implemented to search each node. A flexible buffering scheme allows nodes to be retained in memory until the space is needed. If you expect access to be somewhat ordered, increasing the bufCt will reduce paging.